Sanius Health•Senior data engineer
Healthcare cloud data platform
Unified wearable event streams and scheduled operational feeds into one governed platform for analytics and product reporting.
Read the breakdown
Forward deployed engineer for AI, data, and production systems
Forward deployed engineer for teams building AI products and data-heavy software. I scope the problem, build the system, and get it live.
Data + infrastructure
This is the part that usually breaks first if it is weak: pipelines, orchestration, cloud boundaries, observability, and migration work that has to keep running after launch.
Typical stack
Unified wearable event streams and scheduled operational feeds into one governed platform for analytics and product reporting.
Built a Bronze/Silver/Gold pipeline for clinical and wearable data so sensitive analytics could move from raw capture to decision-ready models with governance built in.
Selected work
A few examples of what I owned, what had to work, and what changed after it shipped.
Work inside real constraints
Own the build end to end
Ship across app, data, and infra

Built an open-source macOS developer tool for persistent local workspaces, terminal sessions, and repo context.
Native macOS workspace switcher for folder-backed local development.
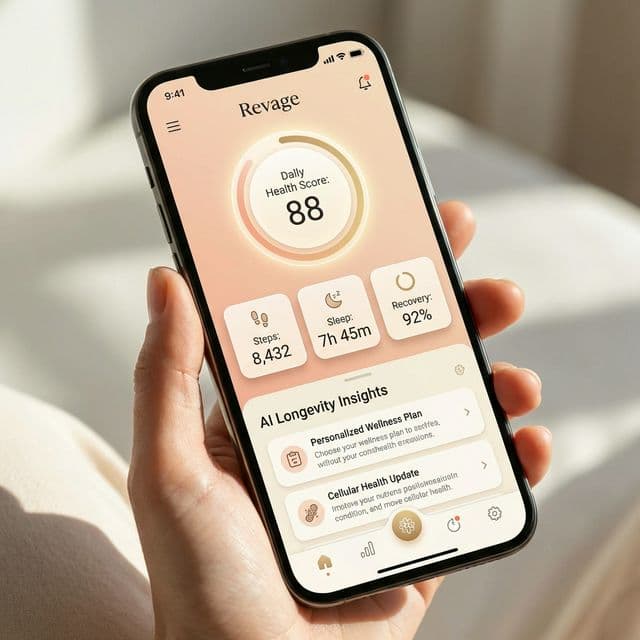
Shipped an AI health product that turned wearable data, behavior signals, and recommendations into a daily product loop.
Longevity app that turns wearable and habit data into clear daily guidance.

Built SaaS analytics software that made software spend, usage, and ROI clear for finance and ops teams.
SaaS analytics product for understanding spend, usage, and ROI across tools.
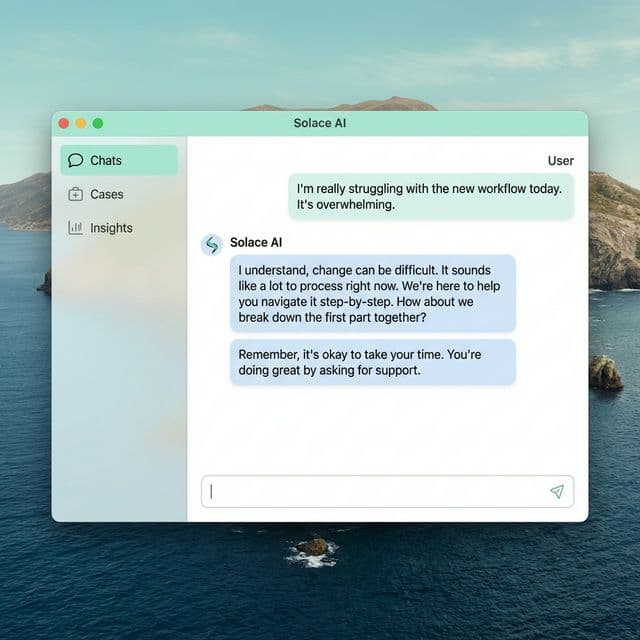
Built an AI companion product with stronger trust, guardrails, and response quality in production.
AI companion experience designed around warmth, clarity, and safety.
Current experiments
Early products, internal tools, and open-source ideas that are still being tested before they deserve a deeper write-up.
Fast bets, sharp first versions, and honest iteration.
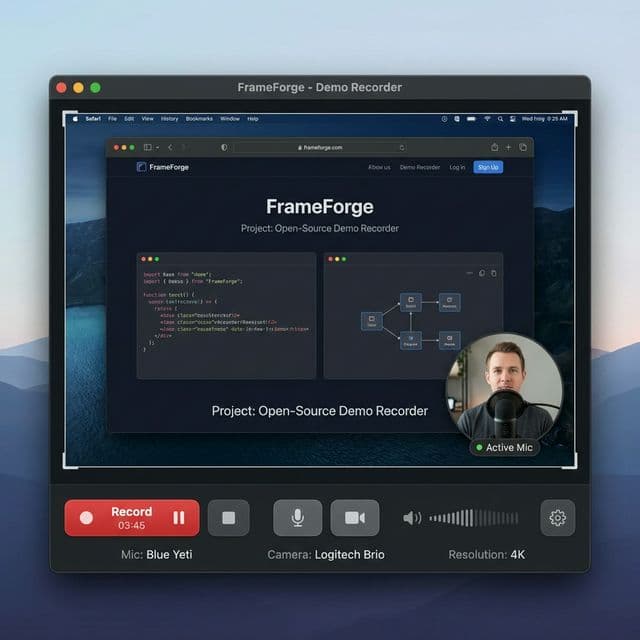
Open-source demo recorder that captures your screen and your narration in one take.
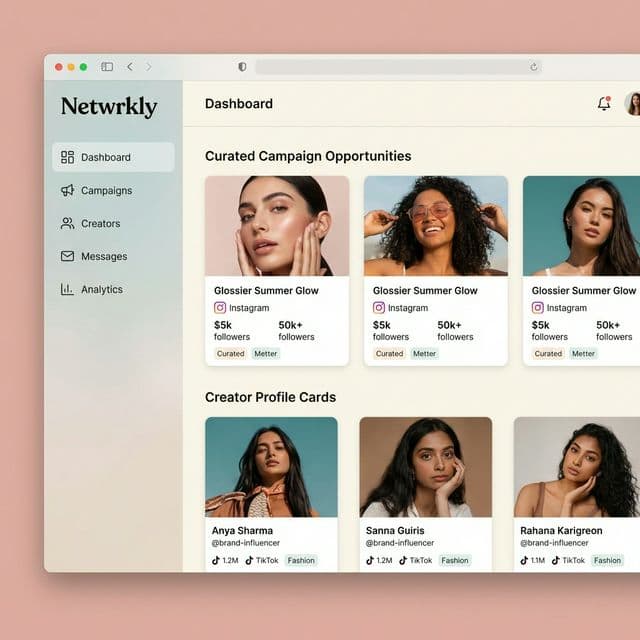
Marketplace for matching brands and creators around campaign fit and execution needs.
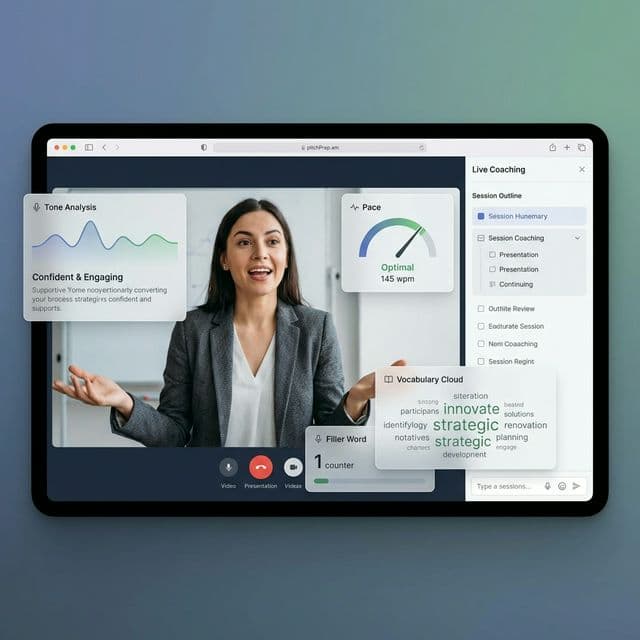
AI speaking coach focused on clarity, confidence, and delivery under pressure.
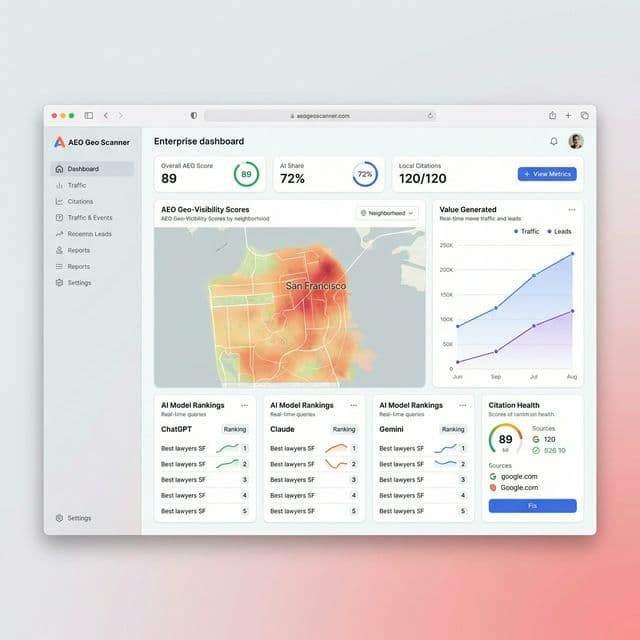
Visibility tool for improving presence in AI answer engines and local search surfaces.
Contact
I work best with small teams that need fast decisions, solid execution, and systems that keep working once they are live.
Best first note: what you are building, what is stuck, and what needs to work in production.